This guide provides a detailed breakdown of the “Crawled, currently not indexed” status in Google Search Console. It can tell you a lot about your site — if you know what it shows, when it appears, and what it actually means.
From this guide, you will learn:
- What the status “Crawled, currently not indexed” means
- How “Crawled, currently not indexed” differs from “Discovered, currently not indexed”
- When “Crawled, currently not indexed” is perfectly normal
- The reasons for “Crawled, currently not indexed” on content pages
- When “Crawled, currently not indexed” Means Trouble — and What’s Causing It
- How to fix “Crawled, currently not indexed”
After spending countless hours analyzing websites affected by Google penalties, I noticed a recurring pattern — the “Crawled, currently not indexed” status often plays a central role in diagnosing these problems.
“Crawled, currently not indexed” is one of those indexing statuses that might look harmless — especially when it applies to technical or utility pages that weren’t supposed to be indexed anyway. But when content pages get flagged with this status (blog posts) it can be an early symptom of serious issues that may later destroy your organic traffic.
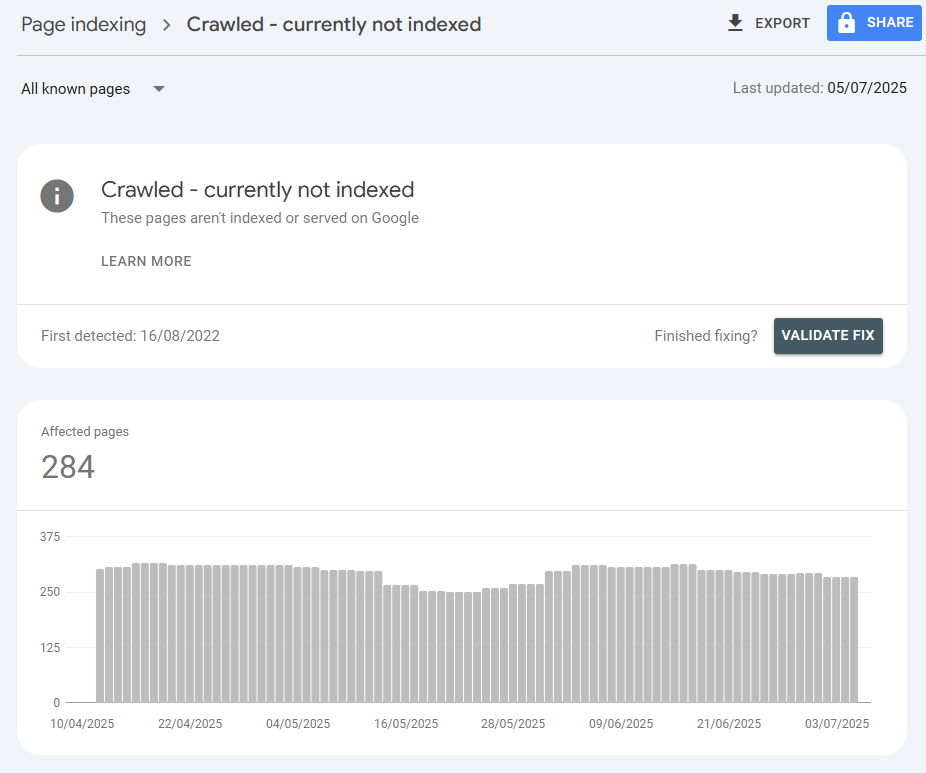
And when hundreds or even thousands of content pages receive the “Crawled, currently not indexed” status, it may indicate that Google has a low overall assessment of your website. Google crawls your content but refuses to include it in the index, judging it not valuable enough to be indexed. Why this happens — and what you can do about it — is what we’ll explore below.
I’ve often heard the opinion that resource saving — specifically crawl budget limitations — forces Google to assign the “Crawled, currently not indexed” status, refusing to index the page. In reality, that’s not the case.
If a website is genuinely experiencing crawl budget issues across the entire domain, the affected pages will be labeled differently — with the status “Discovered, currently not indexed”. This means Google has learned about the existence of the page but hasn’t yet attempted to crawl it. In contrast, “Crawled, currently not indexed” means the page has already been crawled.
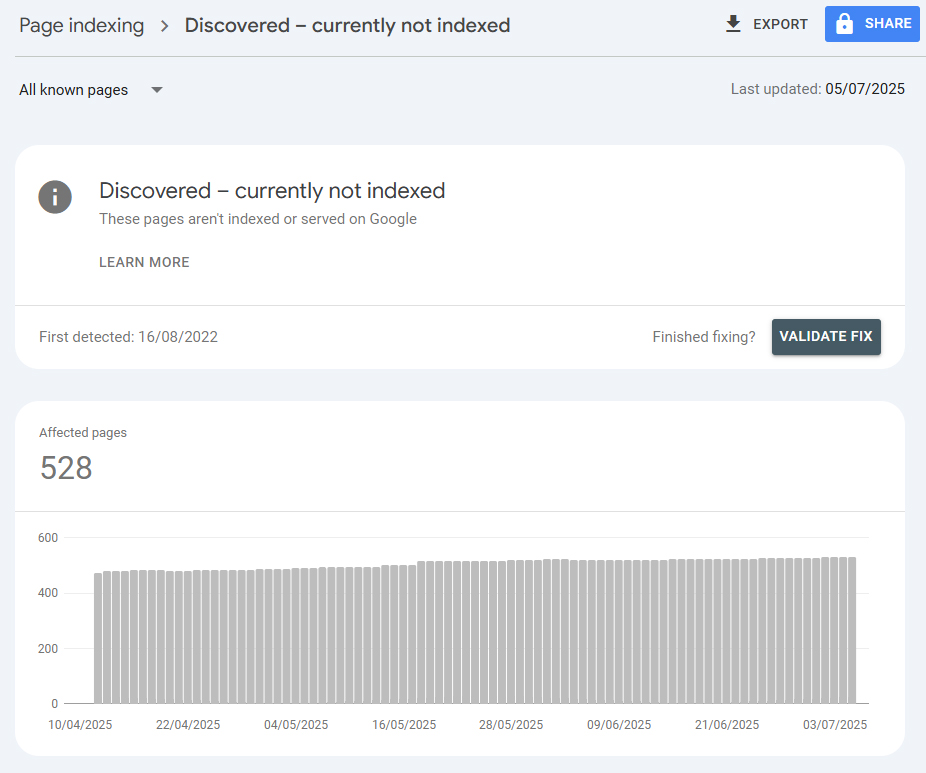
So why would Googlebot decide not to crawl a discovered page, even though it knows about it? First, it’s important to understand that this is not a final decision but a temporary one. Over time, Google may return to the page and crawl it. This often happens when a large number of pages are uploaded to the site at once, and Google delays crawling by placing those pages in a queue. During that time, they will show the status “Discovered, currently not indexed”.
The second reason could be technical issues that occurred during the attempt to crawl the page — for example, server errors. Or, when the server responds too slowly, and crawling multiple pages could further degrade performance. In such cases, Google may postpone the crawl.
The third reason is the very crawl budget limitation mentioned earlier. But this is quite rare and typically applies only to very large websites with over half a million pages. As Google’s Gary Illyes officially stated: “90% of websites don’t need to think about crawl budget”.
Another reason is the poor quality of the entire website, after which Google decides not to waste resources on crawling and marks such pages as “Discovered, currently not indexed”. This is a rather curious case because Google isn’t evaluating the current page (since it hasn’t crawled it yet) but is predicting its likely quality based on the analysis of other pages on the website. That is, it’s enough for Google to crawl part of the site to conclude that further crawling is unnecessary — because there’s a high probability that the rest of the pages are of similarly low quality.
In fact, when Google automatically refuses to index certain pages and labels them with the status “Crawled, currently not indexed”, it can actually be beneficial for your website.
Google is not supposed to index absolutely every page of your site. This behavior protects your site from having unimportant pages enter the index -pages that were never meant to be indexed in the first place.
Specifically:
- Pagination pages (?page=2, ?page=3, etc.) — these contain no unique content and simply duplicate core sections. Their indexing only dilutes the site’s structure.
- Internal search result pages (/search?q=…) — Google doesn’t index these by default, since their content is unstable and depends entirely on the query.
- Feed pages (/feed/, /post/feed/) — they duplicate content intended for subscribers, not for search results.
- Product filter pages (/shop?color=blue&size=M) — especially when there are many filters and the page content changes minimally. These can generate thousands of URLs with nearly identical content.
- CMS utility pages (/cart/, /checkout/, /admin/, /wp-json/) — these are functional parts of the website and not meant to appear in search.
- Calendar and archive pages (/2025/07/, /category/news/page/4) — they don’t contain unique content; they merely group together posts that are already indexed.
- Sorting parameter URLs (?sort=asc, ?orderby=date) — if proper canonical tags are not set, these create duplicate content and interfere with prioritizing the right pages.
- Empty or unfinished pages — these are templates automatically generated by your CMS, but no content has yet been uploaded to them.
So if you find that your “Crawled, currently not indexed” pages mostly fall into these categories, it’s absolutely normal. In fact, that’s how it should be.
What I do recommend, however, is reviewing the pages listed under #8 — you might consider deleting some of them or setting up a 301 redirect to a more relevant page.
Having the types of pages listed in the previous section show up as “Crawled, currently not indexed” is an understandable and logical situation — though of course not a pleasant one.
But there are cases when content pages with sufficient text, proper internal linking, clean URL structure, and no visible technical issues -pages that visually appear to deserve attention — suddenly drop out of the index and receive the “Crawled, currently not indexed” status.
I first noticed this issue about two years ago. At first, I thought it was a temporary glitch in Google’s system. But over time, more data appeared, and the situation became clearer.
Let me illustrate this with two client cases: one content-based review site and one ecommerce site.
In the first case, the review website was publishing a large number of content pages generated using AI, without much effort put into improving or editing them afterward. As a result, the pages were unique in wording but not truly original, since they merely rephrased what had already been published on other websites within the same niche. The actual usefulness of such reviews for readers was highly questionable. In addition, some of the articles weren’t even particularly relevant to the overall theme of the website.
As a result, Google deindexed many of these pages, marking them as “Crawled, currently not indexed”. Out of nearly 1000 original pages on the site, fewer than 300 remained indexed.
But the key issue is that even those 300 pages still in the index saw a significant drop in traffic right after one of Google’s core updates. Thus, the client’s website received an algorithmic Google penalty for scaling content that provided no real value and usefulness to readers.
The situation with the ecommerce website was different in nature but led to the same outcome. Many product pages contained non-unique content. In most cases, the descriptions were copied from official brand websites or from Amazon. In addition, the content volume was often insufficient — limited to just a few short paragraphs.
As a result, these pages were also removed from the index and marked as “Crawled, currently not indexed”. Over time, the site’s overall organic traffic declined — just like in the first case.
At RecoveryForge, since we deal with many websites affected by Google penalties, I had enough examples to analyze the correlation between mass deindexing of existing pages (marked “Crawled, currently not indexed”) and a general decline in search traffic — even on the pages that remained indexed.
Here are some patterns I observed:
Websites that were later penalized by Google for content issues often had prior problems with content pages being deindexed. And those pages were typically marked as “Crawled, currently not indexed”.
In the vast majority of cases, the root cause was the publication of bare AI-generated content that wasn’t original enough and lacked real value for readers. A user could read essentially the same thing in any other article on the topic published elsewhere.
The second most common cause was insufficient content volume. Google has previously stated that word count alone is not a ranking factor. But in this context, low word count correlates with thin content — pages that don’t provide enough information to satisfy user queries. This is especially problematic when the content is not original, or worse — copied, as was the case with our client’s ecommerce store.
Another important point: the process of pages dropping out of the index with the “Crawled, currently not indexed” label was not immediate. It happened gradually, over the course of several months. And if site owners (or their SEOs) had paid attention to the growing number of such pages, they could have taken action to prevent the Google penalties — before they actually hit.

